|
| |||
|
|
| This Document | |||||
| SummaryPlus | |||||
| Full Text + Links | |||||
| ·Thumbnail Images | |||||
| PDF (592 K) | |||||
| Actions | |||||
| Cited By | |||||
| Save as Citation Alert | |||||
| E-mail Article | |||||
| Export Citation | |||||
Inter-domain routing: Algorithms for QoS guarantees
Samphel Norden ,
, 
Lucent Bell Labs, Room 4F-529, 101 Crawfords
Corner Road, Holmdel, NJ 07733, USA
Received 16 March 2004;
revised 16 November 2004; accepted 28 January 2005. Responsible
Editor: E. Ekici. Available online 23 March 2005.
Quality-of-Service routing satisfies performance requirements of applications and maximizes utilization of network resources by selecting paths based on the resource needs of application sessions and link load. QoS routing can significantly increase the number of reserved bandwidth sessions that a network can carry, while meeting application QoS requirements. Most research on QoS routing to date, has focused on routing within a single domain. BGP, the de facto standard for inter-domain routing provides no support for QoS routing, and has well-documented performance related issues that lead to its inadequacy to support QoS. This paper proposes new approaches to inter-domain routing for sessions requiring guaranteed QoS. The performance-scalability tradeoff is explored via extensive experiments on the proposed algorithms. Our extensive experiments on realistic intra-domain ISP topologies as well as inter-domain settings, show that the proposed algorithms achieve at least an order of magnitude gain in performance (blocking probability) over current mechanisms, while remaining scalable and easy to deploy.
Keywords: Quality of service; Reservations; Inter-domain;
Routing ![]()
The need for timely delivery of real-time information over local and wide area networks is becoming more common due to the rapid expansion of the Internet user population in recent years, and the growing interest in using the Internet for telephony, video conferencing and other multimedia applications. Choosing a route that meets the resource needs of such applications is essential to the provision of the high quality services that users are coming to expect.
In this context, it is important to distinguish datagram and flow routing. In datagram routing, packets of a session may follow different paths to the destination. In flow routing, all packets belonging to an application session follow the same path, allowing bandwidth to be reserved along that path, in order to ensure high quality of service. Because many thousands or even millions of packets are typically sent during a single application session, flow routing occurs far less often than datagram routing, making it practical to apply more complex decision procedures than can be used in datagram routing.
The current Internet follows the datagram routing model and relies on adaptive congestion control to cope with overloads. Internet traffic is forwarded on a best-effort basis with no guarantees of performance. This can result in wide variations in performance, resulting in poor service quality for applications such as voice and video. Furthermore, Internet routing is typically topology-driven instead of being load-driven. This approach does not allow traffic to be routed along alternative paths, when the primary route to a destination becomes overloaded. While the application of load-sensitive routing to datagram traffic can cause hard-to-control traffic fluctuations, it can be successfully applied to flow routing, since reserved bandwidths sessions typically have holding times of minutes, effectively damping any rapid fluctuations in routes. Note that the use of the term “flow” in the rest of this paper also applies to aggregates of smaller “micro-flows” which are often bundled, when routing across domains.
The most prominent inter-domain routing protocol in the current Internet is the Border Gateway Protocol (BGP) [1]. BGP is a path vector based protocol, where a path refers to a sequence of intermediate domains between source and destination routers. BGP suffers from a number of well-documented problems, including long convergence times [2] and [3] following link failures. BGP adopts a policy based routing mechanism whereby each domain applies local policies to select the best route and to decide whether or not to propagate this route to neighboring domains without divulging their policies and topology to others.
The immediate effect of the policy based approach is to potentially limit the possible paths between each pair of Internet hosts. BGP does not ensure that every pair of hosts can communicate even though there may exist a valid path between the hosts. Also, since every domain is allowed to use its own policy to determine routes, the final outcome may be a path that is locally optimal at some domains but globally sub-optimal due to the lack of a uniform policy or metric used to find an end-to-end route. This point is highlighted by [4] and [5], where a majority of paths that are picked by BGP do not represent the optimal end-to-end paths. The authors define “optimal paths” by hop count in [4]. Their results show that for 50% of the BGP paths, there exists an alternate path with at least 5 less hops. In [5], different measures of path quality such as loss rate, bandwidth and round-trip time, consistently indicate that 30-80% of paths actually have an alternate path with significantly superior quality than the default path chosen by BGP.
The sub-optimality of BGP is primarily due to most domains defaulting to hot potato routing, in which each domain in the end-to-end path, tries to shunt packets as quickly as possible to the next network in the path, rather than selecting routes that will produce the best end-to-end performance for users. This characteristic is clearly undesirable, even for datagram traffic, and is particularly problematic for sessions that require high quality of service. Thus, there is clearly a critical need for a QoS routing mechanism that allows guarantees across domains.
Most research in QoS routing has focused on routing within a single domain. While the intra-domain problem is important, it is arguably even more important to address the QoS routing problem at the inter-domain level. Also, it is not feasible to directly extend protocols for intra-domain routing to the inter-domain context. While scalability is an even larger concern due to the sheer number of nodes and domains, the issue of peering relationships can constrain the nature and periodicity of information exchanged between domains. Whereas, an intra-domain protocol operates in a smaller network where all routers cooperate such that information about the entire topology can be conveyed to each router, this is not possible when routing across domains. Providing QoS routes across domains is made harder by the fact that each domain has a constraint on the information that it exchanges with other domains. This can affect the routes that are advertized by BGP speakers and can also isolate domains even though valid paths exist between them. Thus, there is a necessity to develop QoS routing approaches that are backward compatible with current networks while using simple mechanisms to avoid scalability problems and to facilitate deployment.
New inter-domain QoS routing approach: We begin with the observation that the peering links that connect distinct routing domains are typically the primary congestion points or bottlenecks for network traffic [6].1 Managing the resource use at such points of congestion is clearly critical to providing end-to-end quality of service.
Our strategy for inter-domain routing has two parts. In the inter-domain part, a loose source route2 is selected by the router at origination point of the session. This source route specifies the domains through which the route is to pass and the peering links used to pass from one domain to the next. Within each domain, paths are selected between the ingress and egress points, using domain-specific routing policies. This is referred to as the intra-domain part. This decomposition of the end-to-end routing problem respects each domain’s right to maintain the privacy of its internal network configuration and appropriately limits the amount of information that must be taken into account when selecting routes. At the same time, it allows the large-scale characteristics of the route to be selected with appropriate consideration of the status of the peering links.
Privacy issues: While it may seem a violation of privacy to disseminate the peering link information, we believe that it is in the provider’s best interest with several beneficial consequences. For example, providing information about a chronically saturated peering link may mitigate the load on that link. Balancing the load not only increases the QoS to the client, but also creates more revenue to the participating providers (on the end-to-end path), since they are now able to carry more calls with less rejection probability. We discuss this in more detail in Section 6.
Scalability issues: With any QoS routing scheme, scalability is an important criteria. In terms of a real operating environment with thousands of autonomous systems, there will obviously be severe scaling issues if all the peering link information needs to be disseminated. We discuss this issue and its potential solution in more detail in Section 6.
Contributions: In this paper, we propose and evaluate two inter-domain QoS routing algorithms that follow the strategy of improving performance by avoiding bottle-neck peering links. We begin by describing a simple overlay network architecture to enable the QoS routing mechanisms such that no change is necessary to existing mechanisms such as BGP. The first, uses a fairly conventional shortest-path framework, using a cost metric that accounts for both the intrinsic cost of each link and the amount of bandwidth that the link has available for use. The second dynamically probes several paths in parallel, in order to find a path capable of handling the flow. This approach eliminates the need for regular routing updates, since routing information is obtained on-demand. We perform extensive experiments on realistic intra-domain and inter-domain topologies to demonstrate the substantial benefits that can be attained by using our proposed schemes.
There is a significant amount of prior research in the area of intra-domain QoS routing. However, the design criteria for inter-domain QoS routing is different from intra-domain routing, with a special emphasis on scalability. There is an inherent tradeoff between performance and scalability. We believe that this is one of the first papers that extensively evaluates the performance of QoS routing protocols in both the intra and inter-domain context and quantitatively evaluates the tradeoff.
The outline of the paper is as follows. Section 2 motivates and describes two QoS routing algorithms that are extended for inter-domain routing. Performance of these routing algorithms in an intra-domain setting are also presented to demonstrate their benefits. Section 3 extends these algorithms to support inter-domain QoS. Section 4 describes the inter-domain simulation environment and a comprehensive evaluation of the performance of the routing algorithms including a comparison with a BGP based approach. Section 5 enhances the QoS routing algorithms in order to facilitate deployment in current networks. Implementations details along with the processing overheads of deploying the proposed algorithms are presented in Section 6. Section 7 presents prior research in the area and the paper concludes in Section 8.
To ensure the best possible performance in the presence of the full range of traffic conditions, it is important for route selection to be guided by a knowledge of current network state information using metrics such as loss, latency and available link capacity. Available bandwidth in particular is especially critical at the inter-domain level where peering link bottlenecks are critical in determining whether a packet reaches the destination. In this paper, we focus on using available bandwidth as a metric for QoS routing. In this section, we introduce two QoS routing algorithms, which are representative of different classes of routing algorithms that range from routing based on Dijkstra’s shortest path algorithm using link-state/distance vector updates, to dynamic on-demand probing via multi-path routing.
Previous comparative studies have demonstrated that algorithms that consider the path length in the routing decision are superior to ones that do not [7] and [8]. The widest–shortest path algorithm breaks ties between routes with the same path length by picking the path with the largest available bottle-neck bandwidth. However non-minimal routing algorithms such as the distributed shortest–widest path often selects circuitous routes that consume additional network resources at the expense of future sessions which may increase session blocking. Biasing toward shorter path routes is particularly attractive in a large distributed network, since path length is a relatively stable metric compared with the dynamic measurements of link delay or loss rate. Very few schemes however consider both the path length as well as bandwidth in the routing decision. We propose the Least Combined Cost Metric as a cost metric that integrates both the path length as well as the bandwidth into an effective route selection mechanism. Most of the previous link state approaches are severely impaired by “bad” routes picked due to incorrect state information. Our scheme factors in the staleness of link state, and appropriately weights links to minimize the possibility of picking “bad” routes.
However, the inherent drawback of link state protocols of the possibility of using stale link state information [9] still exists and can hamper the selection of the “optimal” path. Thus, there is a need for protocols that use up-to-date dynamic state in route selection. This leads us to on-demand probing using multi-path routing algorithms.
Several multi-path routing algorithms have been proposed as alternatives to single path routing. Most of these schemes use some form of flooding on a per-session basis, placing a large load on both the routers as well as the network. Though subsequent schemes reduce the flooding, there is still a significant overhead, as well as a delay in setting up the route. Additionally, most of these approaches reserve resources in the forward pass over the multiple paths, that can result in blocking other sessions.
Building on hybrid multi-path routing approaches, we propose a simple scheme called the parallel probe algorithm, which has the following features: (1) pre-computes and caches a limited number of alternate equivalent3 paths between source and destination so that routers do not perform route computation on demand, significantly reducing routing overhead and avoiding any flooding; (2) sends probes on these equivalent paths on-demand allowing probes to collect accurate, up-to-date information about the links for route selection without reserving resources, thereby reducing the reliance on stale link information. No state is installed by the probes that allows fast-path router forwarding without blocking any intermediary resources.
Source vs hop-by-hop routing: While it is feasible to use hop-by-hop routing of packets for QoS guarantees by classifying packets appropriately (for example, the IP TOS field, or the Diffserv DS Byte), and maintaining different forwarding tables for each class of packets. A hop-by-hop protocol is also easier to adopt in the current Internet since the current routing approaches (OSPF, BGP) use a hop-by-hop selection mechanism. However, a hop-by-hop approach may choose a local hop optimally but due to a lack of knowledge of the path characteristics downstream, the connection could be rejected. We focus on explicitly routed paths since it is easier to provide guaranteed QoS at the flow level, for a path with reserved resources, than with a hop-by-hop packet routing paradigm.
We will now describe the baseline generalized versions of the new QoS routing algorithms that operate in an intra-domain environment. We present simulation results on a realistic intra-domain topology showing the benefits of the proposed protocols.
The Least Combined Cost Routing (LCC) algorithm is a link state algorithm based on OSPF-TE [10]. Link state update provides information about the bandwidth available for use by reserved bandwidth flows, on all links in the network. This allows each overlay node or router to build up a complete view of the network status, which can be used in making routing decisions. For the rest of this paper, the term “overlay node” is used synonymously with “router”. LCC routes a flow reservation by selecting a least cost path to the destination, at the source router where the reservation request first enters the network, then forwarding the reservation request along this path, reserving resources at each hop. If at some point on the path, the selected link does not have sufficient capacity for the reservation, then the reservation is rejected.
The cost metric used in the path computation takes into account both the distances spanned by the links and the amount of available bandwidth relative to the reservation bandwidth. The cost metric is motivated by the observation that whenever the network is lightly loaded, paths should be selected to minimize the sum of the intrinsic link costs, since this minimizes the cost of the network resources used, and the network delay. When some links are heavily loaded, we want to steer traffic away from those links, even if our most recent link state information indicates that they have enough capacity to handle the flow reservation being setup. The reason for avoiding such links is that in the time since the last link state update, the link may have become too busy to handle the reservation. Rather than risk setting up the reservation on a path with a high likelihood of failure, we would prefer a longer path with a smaller chance of failure.
Table 1 lists several key pieces of notation used in the link cost expression shown below which is referred to as the Combined Cost Metric (CCM).
Notation for cost metric
Term Explanation B Available bandwidth on a link R Reservation bandwidth requested L[u, v] Length (distance) of path joining routers u and v M Bandwidth “margin” where M = B − R
The three parameters, alpha, beta and g determine how the cost of a heavily loaded link increases. Specifically, if the link’s margin (the amount of available bandwidth remaining after subtracting the bandwidth required by the reservation) is greater than g, then the cost of the link is equal to its length. If its margin is less than the threshold g, then its cost increases as the margin shrinks (note the margin may be less than zero). g is chosen to reflect the likelihood that in the time between the last link state update and the arrival of a reservation, the link has become too busy to handle the reservation. Specifically, for margins of g or greater, the probability of making a bad route selection based on stale link state information is minimized.
From Fig. 1, we see that when the margin is large (light loading), then the cost is proportional to the length. However, when the margin falls below the threshold (g), the cost increases quadratically as a function of the margin. A reasonable choice for g is a small multiple of the average reservation bandwidth (R). A large g can result in a pessimistic metric which can unnecessarily penalize links that have sufficient capacity, whereas a small g could lead to poor routes due to stale link state. The parameter β determines how rapidly the cost grows as the margin drops. We experimented with various values of (β, g) and found that a quadratic function (β = 2) and g = 4 × R offers the best performance [11].
Fig. 1. Combined cost metric.
To determine a reasonable choice for the scaling parameter α, consider the appropriate cost increment in a situation where the margin is equal to zero. Note, that in the time since the last link state update, the “true” margin may have either increased or decreased. If we assume that both possibilities are equally likely, then the added cost when the margin is zero should balance the cost of the two different “incorrect” routing decisions that are possible: (1) the link actually has insufficient bandwidth; (2) the link actually has sufficient capacity. The cost of (1) is that the reservation is rejected. This can be expressed as the cost of the resources that the reservation would use if it were accepted and used a minimum length route. If this minimum route length is D, then the cost is DR. The cost of (2) is that an alternate link(path) of higher cost is used, wasting network resources. This added cost is αgβR. Setting this equal to DR and solving for α gives α = D/gβ. To avoid the implied requirement to calculate D and α for each reservation, we simply specify α based on a typical value of D.
In the LCC algorithm, routing information is distributed throughout the network to facilitate the routing of reservation requests. One drawback of this approach is that routers must maintain a great deal of information, much of which is never used. Indeed, if no reservation consults a particular piece of routing information before the next update replaces it, then that piece of routing information served no purpose, and the effort spent to create it was wasted. Furthermore, these schemes rely on the link state distributed from neighbors, which could be stale. Routing using stale link state can severely degrade performance [9]. The parallel probe (PP) algorithm takes a different approach. Rather than maintain a lot of dynamic routing information, it sends probe packets through the network to collect routing information as it is needed. This means that no extraneous routing information must be maintained. Only that information that is relevant to the selection of paths for actual flow reservations is required.
The PP algorithm uses a pre-computed set of paths for each source–destination pair. Probe packets are sent in parallel on all of these paths to the destination, and are intercepted by the last hop router. As the probe packets pass through the network, each router on the path modifies a field in the packet specifying the available bandwidth on its outgoing link. This operation is simple enough to be implemented in hardware, allowing probes to be forwarded at wire speed. Note that the intermediate routers themselves do not store any state. The probe itself carries the requisite state information.
When the probe packets reach the last hop router, it selects the best path for the flow, based on the information received. Each probe packet includes a field indicating how many probes were sent, allowing the last hop router to easily determine when it has received all the probes, in the normal case where all probes are received. If one or more probes is lost, the last hop router will proceed following a timeout. The last hop router selects the shortest path for which the bottle-neck bandwidth is at least equal to the reservation bandwidth, if there is one or more such path. If there is no such path, the reservation is dropped. The initialization step requires routes to be pre-computed between every source and destination.
Pre-computation: We pre-compute the alternate paths between every source–destination pair using a simple algorithm outlined in Fig. 2 using notation defined in Table 2. Initially, we find the shortest path (using link length or hop count) between a given pair of routers in the network and use this as a baseline metric. We then take every intermediate node and verify if the path length via the intermediate node is within some bound of the baseline path and is distinct from the baseline path. If so, we add this path to the set of alternate paths. We also restrict the number of alternate paths so as to minimize the number of probes that are sent.
Fig. 2. Pre-computation of alternate paths.
Table 2.Notation for PP algorithm
It should also be noted that: (1) pre-computation is done only when there are significant changes in link state; (2) on-demand routes are computed using static information (path lengths) about the network topology, which makes the routes relatively robust to fluctuations in path quality. We comment more on the impact of using static pre-computation metrics on the quality of paths in Section 5.3.
We now present simulation results for the LCC and PP routing protocols for the intra-domain context. The network configuration for this simulation study was chosen to be representative of a real wide area network. This network has nodes in each of the 20 largest metropolitan areas in the United States (see Fig. 3) and is a reduced Delaunay triangulation. The advantage of a Delaunay triangulation is that it allows a limited number of alternate paths between a given source and destination without significantly increasing the cost of the overall network. The overall topology resembles the core topology of the NSFNET backbone. The traffic originating and terminating at each node was chosen to be proportional to the population of the metro area served by the node, and the traffic between nodes was also chosen, based on the populations of the two nodes. This leads to the sort of uneven traffic distribution that is typical of real networks. The links in the network are also dimensioned to enable them to carry the expected traffic. Dimensioning links to have appropriate capacity is important for a realistic study of routing, since a badly engineered network can easily distort the results, leading to inappropriate conclusions about the relative merits of different routing algorithms. Note that we do not use a random topology generator with arbitrary links, since results for such topologies are difficult to generalize.
Fig. 3. National network topology.
Link statistics: The link capacities were chosen using a constraint-based network design methodology developed in [12]. The method selects link capacities that are sufficient to carry any traffic configuration that satisfies certain traffic constraints. The constraint-based design method takes a topology and the set of traffic constraints and uses linear programming to find a set of link capacities sufficient to handle all traffic conditions satisfying the traffic constraints, assuming the traffic is routed using shortest paths. This process results in a wide range of link capacities, with the largest capacity link being 32 times as large as the smallest.
Note that for the rest of this discussion, the actual value of the link capacity is irrelevant since reservation values are expressed as a fraction of the link capacity and not as an absolute value making our simulations as general as possible. The smallest link is the link between Seattle and Denver. Specifically, the bi-directional links between Atlanta and Pittsburgh (2.53 times), Houston and Miami (2.84 times), Seattle and San Francisco (3.75 times capacity of Seattle and Denver), Seattle and Minnesota (6.14 times) and St. Louis and Atlanta (6.32 times) and can be classified as potential bottle-neck links The other link capacities are at least an order of magnitude more than the Seattle–Denver link. Requests that traverse the aforementioned bottle-neck links will have a higher probability of being rejected. We emphasize that we are not using an artificial topology with contrived bottlenecks. Rather, we use the actual populations of cities and derive a realistic traffic model that is representative of the expected traffic between cities. Furthermore, any topology that has a high proportion of bottle-neck links is unrealistic since typical ISP topologies have high capacity links with the primary bottlenecks appearing as access and peering links [6].
In the simulations, reservation requests arrive at each node, at rates that are proportional to the population of the area served by the node. The inter-arrival times and the reservation holding times are exponentially distributed. Note that we are NOT simulating the arrival of packets, but the arrival of reservation requests. The destination of each reservation is chosen randomly, but with the choice weighted by the relative population size of the possible destinations.
There are several numerical parameters that are varied in the simulations. Each parameter has a default value. Whenever one parameter is varied in a given chart, the other parameters are assigned their default values. Each session in our simulation is representative of an aggregate reservation or a macro-flow, since it is unlikely that the cost/overheads of a reservation-oriented model is feasible for micro-flows or individual reservations. Furthermore, we assume that sessions have equal priority, and that an ISP maximizes its revenue by carrying as many sessions as possible.
System load computation: Assume that the mean reservation size
expressed as a fraction of the link capacity is b, then
n = 1/b are the number of simultaneous sessions that can
occupy the link. Each connection has an exponentially distributed call duration
μ = 1/MHT. This corresponds to a service rate of nμ. If
requests arrive at a mean arrival rate λ, then the offered load is given
by ![]() . Note that the offered load can be greater than 1
since this simply corresponds to requests arriving at a rate that exceeds the
rate at which requests complete (end of call holding time). Thus, an offered
load of 1.2, simply implies that 16.67% on average will automatically be
rejected on arrival since there will not be enough resources.
. Note that the offered load can be greater than 1
since this simply corresponds to requests arriving at a rate that exceeds the
rate at which requests complete (end of call holding time). Thus, an offered
load of 1.2, simply implies that 16.67% on average will automatically be
rejected on arrival since there will not be enough resources.
Protocol parameter settings: The default value of the mean holding time (MHT) which is 60 time units. In the charts, the link fraction is the ratio of the reservation bandwidth to the bandwidth of the smallest capacity link in the network (the default value of the link fraction is .05 or 5% of the smallest link). The default update period (time between state updates) is 30 units for LCC. The default number of alternate paths on which PP probes is 6.
Performance metrics: The primary metric is the Rejection Fraction (fraction of requests rejected) which is inversely proportional to the ISP revenue. We also define the threshold for a given routing algorithm to be the offered load at which the rejection fraction equals .001. since these are anecdotally typical operating levels for ISPs.
Routing algorithms: Apart from LCC and PP, the results also include (1) MH, a minimum hop count algorithm which computes the shortest path using Dijkstra’s algorithm with hop count as the metric;, (2) PRUNE, a variant of MH that first removes links that lack the bandwidth to carry the reservation, and then computes the shortest path using hop count; (3) WSP, widest–shortest path algorithm [13] and [14], which maintains a set of alternate paths between every source and destination arranged in increasing order of hop count. When a request arrives, the path with the largest bottle-neck bandwidth is picked from the set of paths with the shortest hop count.
Blocking probability: Fig. 4 compares the blocking probability observed for several different routing algorithms, including the LCC and PP algorithms. The result shows that the LCC and PP algorithms significantly outperform the other algorithms, with LCC performing slightly better than PP.4 The MH and PRUNE algorithms perform much worse than the other algorithms, showing that QoS routing can provide substantially better performance than conventional methods. traditional routing. Additional results for these algorithms can be found in Ref. [11].
Fig. 4. Rejection fraction of the QoS routing protocols.
Having shown the benefits of the intra-domain versions of LCC and PP, we will now proceed to extend them to support routing across domains. We note that primarily due to the reasons of ISP privacy, it is not possible to directly use the intra-domain versions in inter-domain environments. In the following sections we will describe inter-domain versions of LCC and PP and evaluate them extensively on realistic inter-domain topologies.
The objective of the proposed inter-domain routing algorithm is to select a loose source route, joining a flow’s endpoints. Since peering links are often congestion points for network traffic, careful selection of peering links can have a significant impact on the probability of success. Because the inter-domain route selection must be done without the benefit of detailed knowledge of each domain’s internal configuration, it’s necessary to estimate the amount resources or the cost incurred by a flow when it traverses a domain. In this section, we extend both the LCC and PP probe algorithms and describe means to estimate the intra-domain cost while performing QoS routing across domains. We begin with a description of a simple overlay network architecture that would enable the QoS routing mechanisms presented in this paper.
The key component to enable this kind of QoS routing is an overlay node architecture to perform the specialized peering link state dissemination as well as source routing that is critical to the routing mechanisms presented in this paper. Essentially, since BGP cannot be used to disseminate the peering link state that is essential to our QoS routing mechanisms, we assume the use of an overlay network whereby overlay nodes would probe other overlay nodes to obtain the peering link state. This requires the careful placement of overlay nodes to approximate the peering link information. Essentially, a physical peering link’s state (available bandwidth) is conveyed to the overlay node in that domain. This overlay node then conveys the peering link information to other overlay nodes in other domains.
It is also possible for the overlay node to probe the available bandwidth of the peering link using tomography based techniques [15], [16] and [17]. These techniques are based on packet-pair or packet-train probing where bursts of equally spaced packets of uniform size are injected into the path of interest and available bandwidth information is inferred based on the relationship between the input inter-packet gap and the observed gaps in the output.
For now, we assume that the AS provides the peering link information to the overlay node. We examine the implications in more detail in Section 6.
Fig. 5 shows the two-level hierarchy that we leverage to disseminate peering link state as well, as well as for routing packets of a flow. As can be seen from the figure, an overlay node can select a particular peering link by selecting the overlay nodes attached to the appropriate underlying peering nodes. For actual flow routing, all packets are conveyed to the overlay node in the local domain, which then uses the virtual overlay topology to pick a source route of domains including a peering link-specific path. This is achieved by picking intermediate overlay nodes that are “adjacent” to the selected peering links. The “adjacency” is used to ensure that picking a particular overlay node pair in different domains would force all traffic to go via a particular peering link between those domains.
Fig. 5. Overlay network architecture for QoS routing.
It is important to note that the proposed architecture does not rely on BGP to perform routing. More importantly, the overlay node can flexibly probe for any QoS metric including latency, jitter, etc. We discuss the overlay architecture in more detail in Section 6. For the rest of the discussion, we assume the overlay nodes perform the peering link state dissemination along with the actual forwarding of packets belonging to a flow along a source route chosen by running the QoS algorithms presented in this paper at the overlay nodes. Also, we will use peering nodes to refer to the peering “overlay” nodes when describing the algorithms.
The inter-domain LCC algorithm includes two parts. One part distributes information about the peering links that join domains. The peering link information includes the intrinsic costs of the peering links (characterized here by the links’ physical length) and their available capacity. Peering link information can be aggregated to improve scalability, but we do not address the aggregation problem here. Recent works [18] and [19] mention the traffic engineering extensions proposed for OSPF can be extended to BGP. In our case, it is sufficient if the overlay router advertises the bottle-neck bandwidth attribute on a path to another domain’s overlay node. This information is sufficient in determining the quality of the path. Essentially a router would compare the attribute advertized by its neighbor with the bandwidth on its own peering link to that neighbor and set the path attribute to the lower of the two.
It should be reiterated that only the peering node information is exchanged across domains. If there are a large number of peering nodes, a small number of overlay nodes that are adjacent to peering nodes can be designated to behave in a manner similar to BGP speakers. The second part of the inter-domain LCC algorithm makes per-flow routing decisions. Conceptually this is done by computing a least cost path between the endpoints.
The cost of a path is defined to be the cost of the peering links on the path (computed using the combined cost metric, introduced in the previous section), plus the estimated cost of the segments within each domain on the path. We now describe the manner in which the intra-domain segment costs are estimated.
• Geographic estimation (GEO): The geographic estimation method uses the geographic length of the path segment within a domain, as the estimated cost. This implies that the distributed state information include the geographic coordinates of the routers at the ends of peering links. Because this information is static, it need not be updated frequently. We note that there is a difference between the geographic length of a path between two nodes, and the actual physical path length that is comprised of real links between two nodes. The benefit of this approach is that it does not need any additional link state information, and can be easily deployed, since the information used is static and not proprietary.
• Static Path Estimation (G-SP): The G-SP algorithm assumes more accurate static information in the route selection process. Specifically, this scheme assumes that intra-domain routes are computed using real physical path lengths, as opposed to using geographical approximations. This approach is reliant on static path lengths between ingress/egress node pairs of domains, which may change at very long time scales allowing infrequent link state updates on path lengths.
• Aggregating Path Information: The path length information can be aggregated and conveyed by edge routers to other domains. Assume there are x peering routers in a particular domain. Thus, there are O(x2) paths that need to be computed to find the path length. However, one can choose the top k maximally disjoint paths and average the hop-count information to be conveyed to other domains. The choice of the top k paths would be based on the available link capacity of the bottle-neck link on each of the paths. With changes in network topology, it is only necessary to recompute the paths if bottle-neck links change. Specifically, a list of bottle-neck links can be compiled ordered based on the available link capacity. Only if the links with the highest available capacity fail, would paths need to be recomputed and re-averaged. Otherwise, the intra-domain algorithm would continue to use the links with the most available capacity. We do not consider path lengths (hop count) as proprietary information. Besides, divulging this information benefits both the provider and the customers.
• True value estimation (TRU): True value estimation is not so much a practical estimation method, as it is a benchmark for bounding the performance of this class of algorithms. In this method, we assume that the cost of the path within each domain is calculated assuming that all links are assigned a weight based on the combined cost metric (Eq. (1)). Effectively, this scheme assumes that information about physical link lengths as well as the available link capacity disseminated for all links across all domains. The combined cost metric is then used to determine the path costs within each domain. We reiterate that this approach is not intended to be applied in practice, due to the sheer volume and frequency of the information that needs to be exchanged.
Algorithm Operation: Fig. 6 shows the operation of GEO and G-SP. The source creates a virtual graph to the destination, and assigns the peering links a weight determined by the combined cost metric. For example, the link from (ERw, ERx) is assigned a cost C[ERw,ERx] where C[u,v] is as defined in Eq. (1). For intra-domain path segments, we assume the information is aggregated and disseminated as in the G-SP mechanism. In the case of GEO, the information about the coordinates of say ingress router ERx and egress router ERy, is disseminated allowing the cost of a virtual link between them to be assigned a weight determined by the Euclidean distance between them. For G-SP, the weight is the cumulative length of the physical links on the shortest path between them. It should be noted that both these weights are static and need not be distributed repeatedly. For TRU, the combined cost metric is assigned for intra-domain path segments as well using information exchanged across domains. Once the virtual graph is created and the weights assigned, Dijkstra’s shortest path algorithm is executed to obtain a shortest path from the source to the destination at the inter-domain level.
Fig. 6. Routing using LCC based algorithms.
The above shortest path computation only provides a top-level path, since it does not assume the knowledge of individual links. Thus, when a top-level path is picked, and a reservation is initiated, there is a second-level mechanism to compute actual intra-domain paths. For example, a reservation request originating at the source in Fig. 6, will reach the ingress router ERx, based on the top-level path that is selected. At this point, the ingress router could use the shortest path tree computed using the LCC cost metric (for intra-domain routing), to reach the egress router, ERy. The decoupling of inter-domain and intra-domain path computation allows any metric could be used in this case as per policy based routing.
The TRU algorithm assumes that the inter-domain LCC algorithm is combined with the use of LCC at the intra-domain level, as well. However, we reiterate that TRU is not a practical scheme and is solely meant to provide an upper bound on the performance of SPF based algorithms. Also, the use of LCC at the inter-domain level does not require the use of LCC (or any other specific algorithm) at the intra-domain level. Due to policy constraints, we expect that it is difficult, if not impossible, to impose the use of a consistent end-to-end metric for selecting a QoS constrained path.
In this section, we extend the PP algorithm for inter-domain QoS routing. As in the intra-domain context, the PP algorithm involves the transmission of probe packets from the origination point of a flow along several pre-computed inter-domain paths to the destination point for the flow. These inter-domain paths are loose source routes specified at the overlay network level, which specify the domains to be traversed and the peering links used to pass between domains (again, this is done indirectly by choosing the appropriate overlay nodes attached to the chosen peering link). As the probes pass along the path, they gather status information that is used by the router at the destination end, to determine the best path for the flow to take. For the rest of this paper, we assume that the collected status information is the bottle-neck bandwidth on the path. Other metrics such as queue lengths, link latency could also be measured by the overlay nodes depending on the type of QoS required.
In keeping with our overall framework, different routing methods may be used within the domains. In this section, we focus on the case where parallel probe is used at the intra-domain level, as well as at the inter-domain level. However, we subsequently describe how the algorithm can be used for inter-domain routing in combination with other intra-domain routing mechanisms. To describe this combined algorithm clearly, we distinguish between macro-probes, which are used for inter-domain probing and micro-probes which are used within domains.
Initialization step: The first step is to pre-compute alternate paths between peering nodes. We use the overlay network described earlier, composed of peering overlay nodes that talk to each other. As before, we assume that the available link capacity on peering links is disseminated across domains. In addition, we assume that the physical path length between ingress and egress nodes is also known across domains (similar to the G-SP approach of the previous section). The ingress/egress path length information is static. Once, we have a virtual topology of peering nodes, we use the pre-computation approach for the parallel probe algorithm in the intra-domain case. Effectively, for each peering node pair, we choose an intermediate peering node and construct an alternate path. Routes are computed using static information (path lengths) about the network topology.
Now, links in the Internet fail at random and topology maps would be incorrect. However, we expect that peering links that are typically critical to the revenue of a provider would have better redundancy and fail-over based mechanisms than random links in the Internet. We expect pre-computation is not performed often since the status of peering links would be relatively stable compared to other links. Again, we emphasize that the pre-computation would be redone only if the link actually fails instead of when the link metrics (available bandwidth) changes. For more discussion on the scalability of the pre-computation mechanism, please refer to Section 6.
In the combined algorithm, macro-probes are launched by the router at the origination point of the flow, and the passage of macro-probes through the Internet triggers the transmission of micro-probes within each domain. More precisely, when a macro-probe arrives at the ingress router for a domain, the ingress router launches several micro-probes which pass through the domain to the egress router specified in the inter-domain path contained in the macro-probe. The egress router collects the information in the micro-probes, selects the best path and then forwards the macro-probe along the inter-domain path, after adding to it, information describing the available bandwidth on the selected intra-domain path.
When the macro-probes are processed at the terminating router for the flow, it selects the best path and forwards a reservation packet back along the loose source route. The intra-domain portions of the path are filled in by the individual domains, based on the previously selected micro-probe. This implies of course that the egress router retain this information for a short period of time, so that it is available if and when the reservation packet comes back along the path. Note that this process maintains the private nature of the intra-domain path segments. The only state communicated outside the domain is the available bottle-neck bandwidth on the chosen path. The information stored at routers is location-dependent:
Internal router: A router within a domain stores alternate paths to edge routers in the domain. If there are a relatively large number of edge routers, the internal router can store a single path to each edge router.
Edge router (ID): We designate a router that connects to other peering routers in other domains as an ID or Intermediate Destination router. An ID stores alternate paths to other ID’s within a domain. The ID also stores paths to other ID’s in other domains.
We show a sample request and the probes generated by it in Fig.
7. We will trace out a sample end-to-end path as it traverses domains or
autonomous systems (AS). Initially, micro-probes sent out from the source
reach all the IDs within the AS (for example, reaching
[IDw, IDv]). The ID’s store the path
included so far locally and only advertise the bottle-neck bandwidth or related
cost metrics to other domains, respecting the privacy constraints of the domain.
Next, macro-probes are spawned to other domains
(IDw → IDx  AS3). IDx in turn spawns
micro-probes to reach IDy. IDy stores the
winning probe path locally and then spawns a macro-probe to
IDz AS4.
IDz receives macro-probes from two different domains
[AS1,AS3], and selects the better option which is the
probe from IDv in our example. It spawns micro-probes which
finally reach the destination. After a short period, the winning end-to-end
probe is selected and reservation is initiated on the reverse path
(Dst → IDz → IDv → Src).
AS3). IDx in turn spawns
micro-probes to reach IDy. IDy stores the
winning probe path locally and then spawns a macro-probe to
IDz AS4.
IDz receives macro-probes from two different domains
[AS1,AS3], and selects the better option which is the
probe from IDv in our example. It spawns micro-probes which
finally reach the destination. After a short period, the winning end-to-end
probe is selected and reservation is initiated on the reverse path
(Dst → IDz → IDv → Src).
Fig. 7. Multi-path routing using PP.
In this section, we will first describe the design of an inter-domain topology to evaluate the performance of the inter-domain QoS routing algorithms. We then describe extensive results on the performance of the LCC and PP versions along with enhancements to facilitate their deployment.
In this section, we describe the design of an inter-domain routing network that can be used to realistically evaluate the performance of the QoS routing protocols. The basis for network design is similar to the design of the intra-domain routing network described in Section 2.3. We chose the 30 metropolitan cities in the United States with the largest populations. The overall configuration is formed by combining eight separate networks, each spanning a subset of the cities. Two of the networks have national scope, while the remaining six networks are limited to regional areas.
There are two basic kinds of network providers in this topology: National and Regional ISP’s. We use the following heuristics to pick members of either ISP:
National ISP: A city is considered a member of a national ISP with a probability p = 0.8.
Regional ISP: Once a geographical region is decided for a regional ISP, we locate the approximate center of the region and find the 10 closest cities in order of distance. We then pick these cities to be a member with probability p.
We use a distribution of two National ISP’s, and six Regional ISP’s. The national ISP’s are complete graphs and cover 80% of the network (25 nodes). Among the regional ISP’s, there are three best star topologies (see Fig. 8), two Delaunay triangulations and one complete graph topology (see Fig. 9). A Delaunay triangulation [20] topology allows parallel paths between nodes, while minimizing the number of such parallel paths allowing for a cost-effective topology. A single city can be a member of multiple ISP’s. We capture this by creating a separate virtual node for each domain that includes the city. In such cases, peering links are setup between these virtual nodes. The types of peering links can be classified as customer–provider (Small AS that pays a larger AS for access) and peer–peer (both ASes are of comparable size and find it mutually beneficial to transit traffic through each other). In our topology, each of the six regional ISP’s shared a peer–peer link whenever a city was present in both topologies, and shared a customer–provider link with the national ISP’s at each city present in each regional topology. Furthermore, the 2 national ISP’s shared a peer–peer link at each of the cities that were present in both the ISP’s topology. The entire topology overall has 100 nodes. For more details on the topology, we refer the reader to [11].
Fig. 8. Regional ISP: Best Star (a) Regional ISP: West Coast (b) Regional ISP: South East (c) Regional ISP: North East.
.jpg)
Fig. 9. Regional ISP: Delaunay and Complete Graph (a) Regional ISP 2: West (b) Regional ISP 4: Mid West (c) Regional ISP 3: East.
This diverse mix of topologies allows the simulation results to be applicable to the general topology as opposed to a particular topology. We use a constraint-based design method similar to the approach for the intra-domain routing topology. Since traffic can now either be sent within a domain or across domains, we separately dimension the links for intra and inter-domain routing, and take the sum of the dimensions for the overall network. In the simulation, we ensure that intra-domain traffic is restricted to use the links within the domain, and not use peering links.
Routing policy: Routing policy often dictates how packets are routed both within and across domains. For our discussion, we wanted to show the best case performance of inter-domain QoS routing protocols without the constraints of policy. It should be noted that any policy adopted by a particular domain could potentially restrict the paths available for routing between a particular source–destination pair. However, the details of actual policy are often confidential and are beyond the scope of this paper which deals with the performance aspects of QoS routing.
Protocol parameters: As before, reservation requests arrive at each node, at rates that are proportional to the population of the area served by the node. The inter-arrival times and the reservation holding times are exponentially distributed. Uniform reservation bandwidths are used. The destination of each reservation is chosen randomly, but with the choice weighted by the relative population size of the possible destinations. The traffic in this case is distributed not just among a set of destination nodes, but also among a set of destination domains. The link capacities vary with the smallest being 80 Mbps and the largest being 15 Gbps. With such a large variance, we use a default session bandwidth requirement of 20 Mbps rather than a fixed link fraction. The mean holding time (MHT) is also increased to 120 time units. The update period is 30 time units. The default number of alternate paths on which PP sends probes is 6.
Call blocking probability: Fig. 10, Fig. 11 and Fig. 12 show the performance of the QoS routing schemes. The overall rejection fraction results (Fig. 10) show that PP is clearly superior to TRU (factor of 2 improvement at 10−3) and the GEO algorithm (factor of 8 improvement at 10−3). It is surprising that the PP algorithm is able to outperform TRU in spite of TRU calculating a shortest path on-demand for every request. The TRU algorithm still relies on periodic link state updates and the use of stale link information can result in non-optimal path selection. It should also be noted that with the requested bandwidth (20 Mbps) which is almost 1/4th of the smallest link capacity, it is easier to saturate a link by choosing a non-minimal path. The PP algorithm also is able to pick alternate paths that do not have bottle-neck links in common allowing for better load distribution. It is also possible that the TRU algorithm picks longer paths than necessary (no upper bound on path length) increasing the chance of reservation failure as well as placing extra load that could affect other connections.5
Fig. 10. Rejection fraction for inter-domain QoS routing protocols.
.jpg)
Fig. 11. Rejection fraction for inter-domain QoS (low bottle-neck bandwidth).
.jpg)
Fig. 12. Rejection fraction for inter-domain QoS (large bottle-neck bandwidth).
The GEO algorithm is significantly worse than both TRU and PP. Recall that the GEO algorithm first uses geographical distances to pick peering nodes, and then uses the LCC algorithm within the domain. The use of geographical distances assumes that physical links follow the virtual geographical links which is not the case.
Fig.
11 shows that PP provides significant gains for paths with small bottle-neck
bandwidths ( 150 Mbps), by distributing
the load more effectively and reducing the probability of saturating these
paths. For paths with larger bottle-neck bandwidths (between 600 Mbps and 2.4
Gbps), the gains for PP over the other schemes are consequently less as shown in
Fig.
12, indicating that the combination of stale link state and small links can
cause traditional shortest path protocols to perform poorly compared to a
dynamic multi-path protocol like the PP algorithm.
150 Mbps), by distributing
the load more effectively and reducing the probability of saturating these
paths. For paths with larger bottle-neck bandwidths (between 600 Mbps and 2.4
Gbps), the gains for PP over the other schemes are consequently less as shown in
Fig.
12, indicating that the combination of stale link state and small links can
cause traditional shortest path protocols to perform poorly compared to a
dynamic multi-path protocol like the PP algorithm.
Effect of larger bandwidth requests: Fig. 13 shows the impact of increasing the request bandwidth on the load threshold. The load threshold is the maximum load that can be supported at a rejection fraction of 10−3. PP as expected supports a load of 0.48, TRU a load of 0.2 and GEO a load of 0.1 at the default value of 20 Mbps. The load threshold decreases as the request bandwidth size is increased.
Fig. 13. Variation of threshold with request bandwidth size.
Degrading peering link bandwidth: Fig. 14 plots the ratio of the rejection fractions of GEO and TRU algorithms at a load of 0.4, when varying the bandwidth of peering links. At a degradation factor of 0.5, the link capacity of all peering links is halved. As a lower degradation factor, the peering links are saturated quickly and the choice of the peering link is not as important. This affects the end-to-end TRU algorithm which uses the combined cost metric (Eq. (1)) throughout. Since the GEO algorithm uses the cost metric only for the peering links and the peering links are saturated in a short time, the performance of both TRU and GEO will approximately converge at low degradation factors. Thus, the ratio of their rejection fractions is lower. As we increase the peering link bandwidth, the TRU algorithm starts to outperform GEO and the ratio of the two increases.
Fig. 14. Impact of reducing peering link bandwidth (inter-domain).
Impact of update period: Fig. 15 shows the impact of varying the update period on the load threshold for both TRU and GEO. As expected, the threshold decreases with larger updates due to the use of stale link state information by the route selection mechanism. Both TRU and GEO fall by significant amounts as the update period becomes as large as the MHT. Note that the PP algorithm uses dynamic probing and does not rely on link state updates.
Fig. 15. Variation of threshold with update period (inter-domain).
Impact of α, g on LCC: Fig. 16 shows the accuracy of the g parameter in computing the cost metric (Eq. (1)) for the LCC algorithm. Recall that g is the threshold that triggers adjustment of the cost metric to the cost of the link. As we can see, our choice of g for the simulations shown by the default vertical line is near optimal. Fig. 17 shows the equivalent α term which is also close to the best value that can be picked. A low α term adversely affects the performance since the effect of the margin term in the combined cost metric is not properly accounted for.
Fig. 16. Variation of threshold with LCC parameter g (inter-domain).
.jpg)
Fig. 17. Variation of threshold with LCC parameter α (inter-domain).
One drawback of PP is that if two requests originating at different nodes initiate probes (say r1 and r2) and share paths such that the best possible path for r2 is a subset of the best possible path P for r1. Let us further assume that probing for r1 is initiated before r2, but r2 initiates the reverse reservation before r1. Finally, the destination for r2 is assumed to be one of the intermediate routers on P. It may happen that the reverse reservation for r1 could fail as resources were “stolen” by r2. This can happen since the last hop router on P is unaware of r2. While it is easy to circumvent this problem by installing some sort of soft state in the forward pass of the probe, we first show that this problem does not affect the performance of PP in our inter-domain topology. We modify the PP algorithm to include propagation delays for the probes as they traverse the path. We show the PP algorithm for probe delays of 3 and 5 units compared to the baseline PP algorithm in Fig. 18. It is clear that the delays do not impact the performance of the PP algorithm.
Fig. 18. PP with propagation delays.
However, it is possible that the above scenario may cause the reverse reservation to be rejected. A naive solution is to install transient request state in the forward pass. However, this would potentially block resources on all the parallel paths that are probed for that reservation, leading to a severe loss of utilization. Instead, we propose an alternative that requires some intelligence at the routers. Specifically, we assume that the last hop router, which initiates the reverse reservation, keeps transient state about the statistics (quality) of paths probed for that request. Then, when a request is denied resources on the reverse path, the last hop router initiates a secondary reservation on the next best path. The assumption is that the request can tolerate a large enough call setup time in order for this back-tracking mechanism to find an alternative route. This is not an unreasonable assumption given that flow reservations are for longer durations.
In this section, we present results describing a random Internet topology using Georgia Tech’s GT-ITM [21] topology generator. We used the hierarchical Transit-Stub method to that creates a 2-level hierarchy, with each top-level node representing a transit domain, and with the second level giving each intra-domain graph. Next, attach stub domains to each transit domain. Finally add extra transit-stub and stub-stub edges.
Parameters: The input parameters for the generator were 10 transit domains, with 31 nodes per transit domain, 31 stubs per transit node and 40 nodes per stub. Note that the number of stubs is 9610 and the number of nodes per transit stub is not relevant. In order to adopt a similar dimensioning policy as in our 100 node topology, we mapped each of the 31 transit domain nodes and stub nodes to the 31 largest metropolitan cities in the US. The traffic generated by each stub node was the same. The customer–provider peering link between the stub node and transit node was based on the population of the city. The peer–peer link between transit nodes of two cities was again based on the number of stub nodes attached to the transit node (analogous to the “population” of the transit node). The peer–peer link between two stub nodes is based on the population of the city that represents the stub node. We used a request holding time of 600 time units and each request requires a bandwidth of 1% of the smallest link capacity.
In Fig. 19, we study the performance of the GEO, LCC and PP schemes in terms of the overall rejection fraction for the large inter-domain topology. We see that the performance of the PP and LCC algorithms is as significant as in the smaller topologies. We subsequently show that each routing algorithm can be feasibly deployed using mechanisms described in Section 6 and also comment on the processing overheads.
Fig. 19. Scaling to large AS topologies (9610 domains).
We will now describe enhancements to the aforementioned QoS routing algorithms that explore the tradeoff between performance and algorithm complexity/scalability. We have the PP and GEO algorithms at two extremes. The PP algorithm shows the best performance, but also incurs a size-able overhead due to probes being sent, as well as requiring that all domains use the algorithm consistently for inter and intra domain routing on the end-to-end path. Both of the above do not make the algorithm scalable to large networks with diverse autonomous systems. The GEO algorithm on the other hand uses purely static information that can be obtained without any privacy constraints between domains and is easy to deploy. However, it has significantly worse performance than PP. We seek to improve both algorithms in different ways.
In this section, we describe enhancements that improve the performance of the GEO algorithm while maintaining its ease of deployment. Our first modification (G-SP) is to use real physical link lengths as opposed to using virtual geographical link lengths for routing within the domain.6 While this information is domain specific, it is not necessarily proprietary since another domain will not be able to benefit by information about link lengths, without knowing additional information about the link such as link capacity. Thus, the top-level route selection mechanism uses the combined cost metric at the peering links and physical link lengths at all other links as the link weights and computes the shortest path. As before, intra domain routing is performed using the LCC algorithm. Our next modification (G-PP) is to use the PP algorithm for intra domain routing, while using virtual geographic link lengths for inter-domain routing.
The final step is to combine the two variants above and create a hybrid protocol (G:PP + SP), which uses real physical link lengths to find the inter-domain path of peering nodes (based on G-SP) and uses the parallel probe algorithm for intra domain routing (based on G-PP).
From Fig. 20, we see a 30% improvement of G-SP over GEO. G-PP yields a greater improvement of 40% over the GEO algorithm. The biggest gains are obtained for (G:PP + SP) as shown in Fig. 20. The original GEO and preliminary variants (G-PP,G-SP) are also shown along with the TRU and PP algorithms. As we can see, the hybrid protocol (G:PP + SP) performs almost as well as the end-to-end TRU algorithms and offers a factor of 5 improvement over the baseline GEO algorithm. This version achieves the proper balance between using static information assuring ease of deployment, and performance.
Fig. 20. Performance of a hybrid GEO scheme.
The PP and TRU algorithms reflect two extremes in inter-domain routing. The TRU algorithm is a source routing approach that assumes all information is known at the source and computes an end-to-end route on connection arrival. The PP algorithm sends probes on pre-computed paths to find the best possible route. However, the PP algorithm assumes the existence of alternate routes via pre-computation. Both protocols are applied in a consistent manner across all domains. BGP allows each domain to use its own route selection mechanism leading to locally optimal segments but a globally sub-optimal paths. We realize that forcing every domain to use the same routing protocol is not practical in real networks. In addition, while PP clearly outperforms the other variants, there is still an overhead associated with transmitting probes especially within domains due to the sheer number of alternate paths that are available.
We propose a hybrid version of the PP and LCC algorithms denoted as PPLC that is more scalable than the original PP algorithm. This algorithm uses the macro-probe approach in order to find the top-level path of peering nodes as before. While the baseline PP algorithm used micro probes for routing within an domain, we remove that requirement and allow the domain to use any shortest path mechanism. As our results for intra-domain routing (Fig. 4) have shown, the LCC algorithm performs the best for routing within a domain. Hence, we use LCC for intra-domain routing and use PP for routing between domains. This variant allows an domain to use a simpler intra-domain routing mechanism and is more scalable. The emphasis in the subsequent charts is to see the performance gap narrowing between the PPLC variant and the original PP algorithm. The link state update period is one additional parameter of PPLC that is carried over from the LCC component. The periodicity of routing updates decide the accuracy of the LCC algorithm for intra-domain routing.
Fig. 21 shows the performance of the PPLC variant at different update periods along with the performance of the individual PP and TRU algorithms, where PPLC(x) is PPLC with an update period of x. There is a significant performance boost of PPLC(30) over TRU with nearly 65% improvement at a rejection fraction of 10−3. PPLC(15) obtains a factor of 2 improvement over TRU and the baseline PP algorithm only has a 17% improvement over it. Thus, we see that this hybrid variant not only has significantly reduced overhead compared to both PP and TRU but also provides a balance between the PP and TRU algorithms in performance as well as processing complexity.
Fig. 21. Performance of PPLC compared to PP and TRU algorithms.
Interestingly, the LCC algorithm is marginally better than the PP algorithm in the ISP topology for intra-domain routing (Fig. 4), whereas PP is clearly superior to LCC in the inter-domain scenario from Fig. 10. This is primarily due to the overlapping paths that are chosen by the static pre-computation algorithm described in Fig. 2. If paths overlap, especially at bottle-neck links, this negates the benefits of probing multiple paths, since most of the paths will still have to go through the same bottleneck. The lack of distinct paths collected by the pre-computation algorithm of PP allows LCC to perform better than PP.
Fig. 22 shows the various alternate paths available in the intra-domain setting with choice 1 being the default shortest path. As expected, most requests choose this option and other alternatives share links with this path eliminating them from being chosen frequently.
Fig. 22. Request distribution over individual paths (intra-domain).
Fig. 23(a) and (b) shows specific examples of the limited diversity in path choices for two source–destination pairs in the intra-domain topology. The values in parentheses next to a link show the paths that are sharing that link. As before, the path choice (1) is the default shortest path between the nodes. Other links only have one path using them. For example, in Fig. 23(a), for paths between San Diego and Dallas, 5 out of 6 paths use the link from San Diego to Los Angeles and the link from St. Louis to Dallas. In Fig. 23(b), for paths between Dallas and Houston, a majority of the links belong to at least 3 paths.
Fig. 23. Path sharing examples (a) path sharing between San Diego and Dallas (b) path sharing between Dallas and Houston.
The inter-domain scenario with a more diverse topology as seen in Fig. 24 offers path choices that are more distinct with less sharing of links allowing for a more even distribution of requests.
Fig. 24. Request distribution over individual paths (inter-domain).
We quantitatively capture the links that are shared between the k
paths for the parallel probe algorithm, using the following metric denoted as
Path sharing ratio (PSR), which is the ratio of the ![]() (number of links in path i) to
(number of links in path i) to ![]() (hop count of path i). A ratio of 1 is
ideal since it implies that all paths have distinct links and there is no
sharing between the paths. We obtain a path sharing ratio of 0.82 for the
inter-domain topology and 0.47 for the national network (intra-domain) clearly
indicating that the sharing of links is significantly more in the national
network, limiting the path selection of the PP algorithm. We have performed
additional experiments on other intra-domain topologies that provide more
distinct alternate paths including a torus topology [11].
Our results confirm the above observation that, with reasonable path diversity,
PP always outperforms LCC. It should also be noted that the choices made by
reservations is also dependent on the bottle-neck capacity of the paths. If the
links that are shared between paths have sufficient capacity, this will not have
as much impact on performance as opposed to paths that share bottle-neck links.
(hop count of path i). A ratio of 1 is
ideal since it implies that all paths have distinct links and there is no
sharing between the paths. We obtain a path sharing ratio of 0.82 for the
inter-domain topology and 0.47 for the national network (intra-domain) clearly
indicating that the sharing of links is significantly more in the national
network, limiting the path selection of the PP algorithm. We have performed
additional experiments on other intra-domain topologies that provide more
distinct alternate paths including a torus topology [11].
Our results confirm the above observation that, with reasonable path diversity,
PP always outperforms LCC. It should also be noted that the choices made by
reservations is also dependent on the bottle-neck capacity of the paths. If the
links that are shared between paths have sufficient capacity, this will not have
as much impact on performance as opposed to paths that share bottle-neck links.
However, given that path diversity is not a given assumption in a generalized network, we enhance the pre-computation algorithm for PP in order to minimize the path sharing that is experienced between the pre-computed alternate paths.
Enhanced pre-computation algorithm: Recall that the original
pre-computation algorithm (from Fig.
2) selected an intermediate node i for a given source–destination
pair (s, d), and verified if the alternate path from
s → i → d differed from the default
path from s → d by at least a link and had a length
comparable to the default path. We enhance the algorithm as follows. Let
Ss,d be the set of paths that have been
pre-computed so far for the pair (s, d). Then, we verify the
number of links li that appear in both the potential
path via i, and each path in set Ss,d. If
the length of the potential path is hi, we compute the
ratio ![]() . This ratio is effectively 1 − PSR
defined earlier. The objective is to have to minimize the
PSi term so that very few links from the new path
overlap with existing paths. We then introduce a simulation parameter called the
Path Bound (PB). The algorithm verifies that
PSi PB, and includes
a path in set Ss,d if the verification succeeds,
enforcing that the actual overlap between alternate paths is bounded by the
PB term.
. This ratio is effectively 1 − PSR
defined earlier. The objective is to have to minimize the
PSi term so that very few links from the new path
overlap with existing paths. We then introduce a simulation parameter called the
Path Bound (PB). The algorithm verifies that
PSi PB, and includes
a path in set Ss,d if the verification succeeds,
enforcing that the actual overlap between alternate paths is bounded by the
PB term.
Fig. 25 shows the benefits of the new pre-computation algorithm for the parallel probe. The legends show the original PP and LCC algorithms as well as two new lines where PP(x) indicates that the Path Bound is x (for example, PP(0.8) indicates that there was at most an 80% overlap between the alternate paths for every source–destination pair). PP(0.8) represents the best performance for the parallel probe, outperforming even the LCC algorithm. PP(0.5) actually does worse than the baseline PP algorithm which was not bounded. Essentially, as the PB term decreases, we are constraining the choice of alternate paths. This not only limits the actual number of distinct alternate paths between a source and destination, but also forces the algorithm to choose potentially longer paths, that adversely affect performance.
Fig. 25. Enhancing the pre-computation algorithm.
The three schemes (PP, TRU, GEO) represent protocols which primarily differ in the nature of routing information exchanged. The GEO algorithm uses static information about the geographical distance and is the easiest protocol to deploy of the three schemes requiring minor modifications to OSPF. The TRU algorithm has superior performance for intra-domain routing specifically due to its ability to compensate for stale link state while making routing decisions. However, the staleness of link state increases when path lengths increase (for inter-domain routing) and the delay of propagating the link state to all nodes increases.
As a result, the PP algorithm emerges as the best inter-domain routing algorithm compared to the other schemes. This algorithm uses up-to-date information in the path selection mechanism using information collected by probes. It has also been adapted to suite the isolated nature of each domain whereby probes only carry peering information between domains, while other domain information remains strictly private to the domain.
There are several assumptions made by the routing algorithms presented in this paper that would not normally be realized in current networks. Some of the mechanisms that would be barriers are discussed below.
• Peering link state dissemination: The algorithms proposed in this paper rely on the dissemination of peering link state across providers. Typically peering link arrangements are setup between providers based on service level agreements. The question arises as to why this information should be released across different providers. The primary motivation for providers to share this information: (a) in order to prevent sub-optimal routing and improve the QoS for users, translating to increased provider revenue; (b) to use alternate routes other than the default shortest path or hot-potato routing mechanisms to minimize the probability of congestion.
Within a single domain, all routers are considered as equal and the intra-domain routing protocol announces all known paths to all routers. In contrast, in the global Internet, all ASes are not equal and an AS will rarely agree to provide a transit service for all its connected ASes toward all destinations. Therefore, BGP allows a router to be selective in the route advertisements that it sends to neighbor routers. This is also directly dependent on the peering agreement between two domains. Our suggestion to the existing peering agreement is to augment it with an additional proviso to handle additional traffic which can be decided between providers. This additional traffic translates to increased revenue to the transit AS that would carry it. The only requirement of course, is to convey peering link state to other non-neighbor providers. We believe that the promise of increased revenue would motivate any provider to disseminate peering link state across multiple providers, especially when there are clear monetary incentives for doing so.
In terms of actual mechanisms to disseminate peering link state, one such approach is to use overlay networks such as RON [22] and SPINES [23]. The key idea is to set up overlay nodes at borders of the providers which probe each other. This could require provider cooperation but can also be delegated to a third party overlay provider. The overlay provider would initiate probing of other peering overlay nodes and obtain statistics such as the available link bandwidth, or delay.
Now, the authors of RON mention that their probing scheme which requires the probing of every other overlay node would not scale well in a real environment comprising of thousands of ASes. In order to scale well, the scheme could use different threshold based mechanisms that probe only when there are significant changes in network metrics. Another aid to a scalable architecture is to disseminate probed state in a hierarchical manner similar to a structured peer-to-peer overlay [24]. The combination of a structured hierarchical overlay for scalable probing along with the flexibility of the information exchanged between the overlay nodes results in an overall architecture that would scale well.
• Security issues: One of the key features of the overlay network is the flexibility and customization provided by overlay nodes. In particular, we can enforce several security policies for enhancing and protecting the QoS routing algorithms from malicious attacks. Specifically there are the following mechanisms that we wish to use:
– Authenticated peering link updates: Overlay nodes exchange link state updates using authentication. A certificate based mechanism can be used whereby each overlay node signs a link state update with its certificate to verify the authenticity of the update. It is only necessary for peering overlay nodes to “trust” each other. Thus, instead of requiring a global public key infrastructure which is impractical, we propose that a transitive trust relationship be used whereby the certificate scope is only between two providers.
– Optional encryption: Furthermore, mechanisms such as IPsec [25] tunneling can be established between the overlay nodes that provides both confidentiality (ESP encryption) and authentication/integrity protection to IP packets. This prevents malicious attackers from modifying updates to artificially increase or decrease the importance of a path, or even redirect packets (black-hole attack) to be dropped subsequently. Furthermore, encryption prevents eavesdropping and allowing an attacker to obtain a picture of the network topology.
• Preserving domain privacy: We assume the edge routers of an ASi maintain two separate tables. The first table is the normal routing table reflecting routes within the domain and represents information private to the ASi. The second table is a mapping table with each entry being a 4-tuple <fid, PEERin, PEERout, path> where PEERin,PEERout specify the ingress and egress peering nodes belonging to ASi that are part of the inter-domain path for the flow identified by fid. The path field is the chosen path within the domain.
In the forward pass of the parallel probe, the edge router PEERin sends micro-probes on alternate paths to reach PEERout. Each probe collects relevant intra-domain routing information. The egress router collects information about each probe including the intra-domain route and stores it locally. After waiting for a short time period, information about the best probe is stored at the egress router along with the path field which is filled using the path recorded by the best probe. This state is transient and will be flushed if a reverse path reservation is not made along this segment of the path. The last hop router selects the best probe, reverses the source routed path, and initiates a reservation in the reverse mode. The reserve_probe uses the top-level information maintained in the reversed source route to reach the appropriate peering nodes. A table lookup is made to the mapping table to expand on the intra-domain path allowing the probe to reserve resources within the domain. The intra-domain path is not recorded in the probe during either pass, to prevent AS-sensitive information from being revealed.
• Quantitative processing overhead: To evaluate the computational overhead of pre-computation for the parallel probe, we measured the time to find alternate paths for a given source destination pair for the simulation setup. On a Sparc Ultra-60 server, the computation time of upto six end-to-end paths for a single source for all possible destinations in our 100 node multi-domain topology, is 178 msec. When scaling upto to 10,000 ASes, the computation time is approximately 10 s. Recall that the parallel probe relies on static metrics (hop count) for pre-computation and only requires that the information from the peering link perspective be accurate. Furthermore, we believe that peering links are relatively more robust than regular intra-domain links due to the providers monetary incentive for maintaining the links, combined with redundancy and fail-over mechanisms. Thus, we do not expect pre-computation of peering links to happen often.
In addition to the work mentioned in Section 2, there has been substantial amount of prior research on QoS routing within a domain. We summarize a few of the representative schemes below and examine the complexity and scalability issues that typically act as a barrier to deployment. In particular, we focus on multi-path routing schemes since the PP algorithm proposed in this paper is the best performing algorithm.
There has also been substantial prior research on multi-path routing. One such approach is proposed in [26] for real-time traffic. In this scheme, probes are sent on k alternate paths that simultaneously use k metrics such as hop count to find the best path. The probes are sent between Intermediate Destinations (ID), which are a subset of routers along the least cost path. Each probe reserves resources along its path. From a given ID, the first probe to reach the next ID wins. The resources reserved on the other k − 1 paths are released between the ID’s. The process is then repeated till the destination is reached. This protocol has substantial complexity as it attempts to evaluate k alternate metrics between ID’s. Also, the k probes each reserve resources on the path effectively blocking other requests on each of those paths. Furthermore, in a network where there is significant sharing of links between the alternate paths, resources may be reserved at common links for each of the k metrics creating bottlenecks that increase the blocking probability further.
Ref. [27] proposes a distributed route selection mechanism for real-time messages. The algorithm floods routing messages from the source toward the destination. Each message accumulates the total delay of the path that has been traversed. When a routing message is received by an intermediate node, the message is forwarded only when one of the following two conditions is satisfied: (1) the message is the first such message received by the node, or (2) the message carries a better accumulated delay than the previously received messages. If either condition is true, the message will be forwarded along the outgoing links provided that the delay on that outgoing link added to the accumulated message delay does not exceed the end-to-end delay requirement. This scheme sends up to 2m messages where m is the number of network links, which could become a significant overhead for large networks. Each message reserves resources until a path is selected which could block other messages. In addition, each message reserves resources in the forward pass resulting in blocking subsequent reservation requests.
Ref. [28] proposes multi-path routing and combines the process of routing and resource reservation whereby resources are reserved on multiple paths using an approach similar to flooding for finding the alternate paths. Every node maintains the topology of the network and the cost of every link. When a node wishes to establish a connection with certain QoS constraints, it finds a sub-graph of the network that contains links that lead to the destination with a “reasonable” cost. Such a sub-graph is called a diroute. Reservation requests are flooded along feasible links in the diroute toward the destination and reserve resources along different paths in parallel. When the destination receives a reservation message, a routing path is established. Variants of the above scheme are proposed to reduce the tradeoff between routing time and optimal path selection. The first reservation message to reach the destination decides the path. This could lead to a sub-optimal path since the destination responds only to the first message. This scheme reserves resources on multiple paths and suffers from the same drawbacks of the scheme mentioned above [26]. Furthermore, due to the flooding approach, it is possible that a node that is not part of the selected path does not know that a feasible path has been selected. As a result, resources could be unnecessarily held for a long time period.
Ref. [29] proposes selective probing of links as part of a distributed routing mechanism which does hop-by-hop forwarding. The idea here is to restrict the flooding by only forwarding probes on those links that satisfy QoS for a given flow. Every intermediate node is capable of sending probes in this approach. The algorithm finds a path blindly through competition among probes whereby the first probe reaching the destination wins. This is a hop-by-hop approach whereby probes could take a much longer route to reach the destination since the shortest path may have insufficient capacity.
Ref. [30] proposes a ticket based probing approach which restricts the number of probes sent by a particular node and is meant for delay-based routing. A certain number of tickets are issued at the source according to the contention level of network resources. Each probe is assigned at least one ticket to be valid and only probes with tickets are forwarded. This limits the number of paths searched overall, reducing the amount of flooded messages from the previous approach. The algorithm uses the imprecise state at intermediate nodes to guide the probes along the best possible path to the destination. While this reduces the flooding of the previous scheme, it still has significant overhead. The scheme also assumes global state which is fraught with imprecision due to stale link state information.
A recent work [19] adds a QoS extension to BGP called the available bandwidth index. This proposal requires BGP modification using a new BGP UPDATE message. The authors simulation study is at a very high level where each domain is treated as a single node. There is no evaluation on the combined impact of inter and intra-domain routing. In our work, we propose routing algorithms that do not require changes to BGP, and evaluate this using an engineered network while simulating both intra and inter-domain traversal to as closely approximate real-world behavior.
In this paper, we studied the performance of various QoS routing schemes that cover a wide spectrum from shortest path routing to hybrid multi-path routing schemes. These algorithms are enabled using an overlay network architecture which enables peering link state to be disseminated without relying on changes to existing protocols such as BGP. The architecture also allows flexible injection of metrics that could be used for QoS routing including available bandwidth, and delay, depending on the application. We evaluated these schemes on realistic ISP and inter-domain routing topologies that have links appropriately dimensioned using traffic constraints. We have exhaustively explored the performance-scalability tradeoff in this paper and proposed algorithms that apply to both inter-domain and intra-domain environments. Additionally, we proposed implementation details that will facilitate the deployment of the proposed algorithms in real networks.
As part of future work, we are working on evaluating the proposed algorithms
on a real test-bed using the SPINES overlay node software. SPINES overlay nodes
probe each other using a variety of different metrics and forward traffic based
on the best next hop. We are currently modifying SPINES to perform source
routing and are evaluating the QoS routing algorithms by executing SPINES over
the Emulab [31]
testbed. ![]()
[1] Y. Rekhter, T. Li, A Border Gateway Protocol 4 (BGP-4), Internet RFC-1771, March 1995.
[2] C. Labovitz, A. Ahuja, A. Bose, F. Jahanian, Delayed internet routing convergence, in: Proceedings of ACM SIGCOMM, August 2000.
[3] J. Garcia-Luna-Aceves, Loop-free routing using diffusing computations, IEEE/ACM Trans. Networking (1993) (February).
[4] H. Tangmunarunkit, R. Govindan, S. Shenker, D. Estrin, The impact of routing policy on internet paths, in: Proceedings of IEEE INFOCOM, April 2001.
[5] S. Savage, A. Collins, E. Hoffman, J. Snell, T. Anderson, The end-to-end effects of internet path selection, In Proceedings of ACM SIGCOMM, October 2001.
[6] Akamai Inc. Internet Bottlenecks. Akamai Inc. White paper, 2000.
[7] Q. Ma, P. Steenkiste, Quality-of-service routing for traffic with performance guarantees, in: Proceedings of IFIP International Workshop on Quality of Service, May 1997, pp. 115–126.
[8] I. Matta, A.U. Shankar, Dynamic routing of real-time virtual circuits. in: Proceedings IEEE International Conference on Network Protocols, 1996, pp. 132–139.
[9] A. Shaikh, J. Rexford and K.G. Shin, Evaluating the impact of stale link state on quality-of-service routing, IEEE/ACM Trans. Networking 9 (2001) (2), pp. 162–176 April. Abstract-INSPEC | Abstract-Compendex | $Order Document | Full Text via CrossRef
[10] D. Katz, D. Yeung, Traffic engineering extensions to OSPF, Internet Engineering Task Force, July 1997. Internet Draft.
[11] S. Norden, Improving network performance using QoS routing and deferred reservations. Ph.D. thesis, Department of Computer Science, Washington University, August 2002. Available from: <http://www.sciencedirect.com/science?_ob=RedirectURL&_method=externObjLink&_locator=url&_cdi=6234&_plusSign=%2B&_targetURL=http%253A%252F%252Fwww.arl.wustl.edu%252F%25257esamphel%252FsNorden-2002.pdfhttp://www.sciencedirect.com/science?_ob=RedirectURL&_method=externObjLink&_locator=url&_cdi=6234&_plusSign=%2B&_targetURL=http%253A%252F%252Fwww.arl.wustl.edu%252F%25257esamphel%252FsNorden-2002.pdf>.
[12] J.A. Fingerhut, S. Suri and J.S. Turner, Designing least-cost nonblocking broadband networks, J. Algorithms (1997), pp. 287–309. Abstract | Abstract + References | PDF (255 K) | MathSciNet
[13] R. Guerin, A. Orda, D. Williams, QoS routing mechanisms and OSPF extensions, in: Proceedings of IEEE INFOCOM, March 1997.
[14] G. Apostolopoulos, R. Guerin, S. Kamat, A. Orda, T. Przygienda, D. Williams, QoS Routing mechanismsn and OSPF Extensions, Internet Engineering Task Force, December 1998. Internet Draft.
[15] X. Liu, K. Ravindran, Single-hop probing asymptotics in available bandwidth estimation: sample path analysis, in: Proceedings of ACM Internet Measurement Conference, October 2004.
[16] V. Ribeiro, M. Coates, R. Riedi, S. Sarvotham, B. Hendricks, R. Baraniuk, pathChirp: Efficient available bandwidth estimation for network paths, in: Passive and Active Measurement Workshop, 2003.
[17] M. Jain, C. Dovrolis, End-to-end available bandwidth: methodology, measurement dynamics and relation to TCP throughput, in: Proceedings of ACM SIGCOMM, April 2002.
[18] C. Cristallo, C. Jaquenet, Providing quality of service indication by the BGP-4 Protocol: the QOS_NLRI attribute, Internet Engineering Task Force, March 2002. Internet Draft.
[19] L. Xiao, K.-S.. Lui, J. Wang, K. Nahrstedt, Routing bandwidth guaranteed paths with restoration in label switched networks, in: Proceedings of ICNP 2002, November 2002.
[20] J. O’Rourke, Computational Feometry in C, Cambridge University Press (1994).
[21] E. Zegura, K. Calvert, S. Bhattacharjee, How to model and internetwork, Department of Computer Science, Georgia Tech., March 1997. in: Proceedings of IEEE INFOCOM.
[22] D. Anderson, H. Balakrishnan, F. Kaashoek, R. Morris, Resilient Overlay Networks, in: Proceedings of 18 ACM SOSP, October 2001.
[23] Yair Amir, Cladiu Danilov, SPINES. Center for networking and distributed systems, Department of Computer Science, Johns Hopkins University, December 2003. Available from: <http://www.sciencedirect.com/science?_ob=RedirectURL&_method=externObjLink&_locator=url&_cdi=6234&_plusSign=%2B&_targetURL=http%253A%252F%252Fwww.spines.orghttp://www.sciencedirect.com/science?_ob=RedirectURL&_method=externObjLink&_locator=url&_cdi=6234&_plusSign=%2B&_targetURL=http%253A%252F%252Fwww.spines.org>.
[24] Skype Technologies, Skype: Peer to Peer Internet Telephony. Available from: <http://www.sciencedirect.com/science?_ob=RedirectURL&_method=externObjLink&_locator=url&_cdi=6234&_plusSign=%2B&_targetURL=http%253A%252F%252Fwww.skype.comhttp://www.sciencedirect.com/science?_ob=RedirectURL&_method=externObjLink&_locator=url&_cdi=6234&_plusSign=%2B&_targetURL=http%253A%252F%252Fwww.skype.com>.
[25] S. Kent, R. Atkinson, Security Architecture for the Internet Protocol, Internet Engineering Task Force, November 1998. RFC 2401.
[26] G. Manimaran, H.S. Rahul and C.S.R. Murthy, A new distributed route selection approach for channel establishment in real-time networks, IEEE/ACM Trans. Networking 7 (1999) (5), pp. 698–709 October. Abstract-Compendex | Abstract-INSPEC | $Order Document | Full Text via CrossRef
[27] K.G. Shin, C. Chou, A distributed route-selection scheme for establishing real-time channels, in: Proceedings of High Performance Networking, 1995, pp. 319–330.
[28] I. Cidon, R. Rom, Y. Shavitt, Multi-path routing combined with resource reservation, in: Proceedings of IEEE INFOCOM, April 2000.
[29] S. Chen, K. Nahrstedt, Distributed quality-of-service routing for next generation high speed networks based on selective probing, in: Proceedings of IEEE Local Computer Networks, August 1998, pp. 80–89.
[30] S. Chen, K. Nahrstedt, Distributed QoS routing with imprecise state information, in: Proceedings of IEEE ICCCN, 1998, pp. 614–621.
[31]
B. White, J. Lepreau, L. Stoller, R. Ricci, S. Guruprasad, M. Newbold, M.
Hibler, C. Barb, A. Joglekar, An integrated experimental environment for
distributed systems and networks. in: Proceedings of 5th USENIX Symposium on
Operating Systems Design and Implementation, December 2002, pp. 255–270. ![]()
.jpg) |
Samphel Norden received a B.S. (1998) from Indian Institute of Technology, Madras and Doctor of Science (D.Sc.) (2002) degrees in Computer Science from Washington University in St. Louis. He is currently a Member of Technical Staff (MTS) in the Center for Mobile Networking Research in Lucent Bell Laboratories. His research interests include Mobile Networking, Denial-of-Service detection and prevention, Inter-domain QoS routing, Overlay Networks and Wireless Security. |
|
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Volume 49, Issue 4 , 15 November 2005, Pages 593-619 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Copyright © 2005 Elsevier B.V. All rights reserved. ScienceDirect® is a registered trademark of Elsevier B.V. |
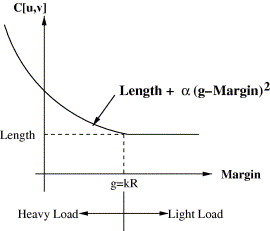

.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)